Publications
publications by categories in reversed chronological order. generated by jekyll-scholar. see latest work on google scholar page.
2025
- Cosmos World Foundation Model Platform for Physical AINVIDIA Cosmos Team: Jiashu XuArxiv, 2025 (CES’25 Best of AI, Best Overall)
Physical AI needs to be trained digitally first. It needs a digital twin of itself, the policy model, and a digital twin of the world, the world model. In this paper, we present the Cosmos World Foundation Model Platform to help developers build customized world models for their Physical AI setups. We position a world foundation model as a general-purpose world model that can be fine-tuned into customized world models for downstream applications. Our platform covers a video curation pipeline, pre-trained world foundation models, examples of post-training of pre-trained world foundation models, and video tokenizers. To help Physical AI builders solve the most critical problems of our society, we make Cosmos open-source and our models open-weight with permissive licenses available via NVIDIA Cosmos-Predict1.
@article{agarwal2025cosmos, title = {Cosmos World Foundation Model Platform for Physical AI}, author = {Team, NVIDIA Cosmos}, author_display = {NVIDIA Cosmos Team: <em>Jiashu Xu</em>}, journal = {Arxiv}, project_page = {https://www.nvidia.com/en-us/ai/cosmos/}, year = {2025} } - World simulation with video foundation models for physical aiNVIDIA Cosmos Team: Jiashu XuArxiv, 2025
We introduce [Cosmos-Predict2.5], the latest generation of the Cosmos World Foundation Models for Physical AI. Built on a flow-based architecture, [Cosmos-Predict2.5] unifies Text2World, Image2World, and Video2World generation in a single model and leverages [Cosmos-Reason1], a Physical AI visionlanguage model, to provide richer text grounding and finer control of world simulation. Trained on 200M curated video clips and refined with reinforcement learning-based post-training, [Cosmos-Predict2.5] achieves substantial improvements over [Cosmos-Predict1] in video quality and instruction alignment, with models released at 2B and 14B scales. These capabilities enable more reliable synthetic data generation, policy evaluation, and closed-loop simulation for robotics and autonomous systems. We further extend the family with [Cosmos-Transfer2.5], a control-net style framework for Sim2Real and Real2Real world translation. Despite being 3.5× smaller than [Cosmos-Transfer1], it delivers higher fidelity and robust long-horizon video generation. Together, these advances establish [Cosmos-Predict2.5] and [Cosmos-Transfer2.5] as versatile tools for scaling embodied intelligence. To accelerate research and deployment in Physical AI, we release source code, pretrained checkpoints, and curated benchmarks under the NVIDIA Open Model License at https://github.com/nvidia-cosmos/cosmos-predict2.5 and https://github.com/nvidia-cosmos/cosmos-transfer2.5. We hope these open resources lower the barrier to adoption and foster innovation in building the next generation of embodied intelligence.
@article{ali2025world, title = {World simulation with video foundation models for physical ai}, author = {Team, NVIDIA Cosmos}, project_page = {https://research.nvidia.com/labs/dir/cosmos-predict2.5/}, author_display = {NVIDIA Cosmos Team: <em>Jiashu Xu</em>}, journal = {Arxiv}, year = {2025} } - Cosmos-Reason1: From Physical Common Sense To Embodied ReasoningNVIDIA Cosmos Team: Jiashu XuArxiv, 2025
Physical AI systems need to perceive, understand, and perform complex actions in the physical world. In this paper, we present the Cosmos-Reason1 models that can understand the physical world and generate appropriate embodied decisions (e.g., next step action) in natural language through long chain-of-thought reasoning processes. We begin by defining key capabilities for Physical AI reasoning, with a focus on physical common sense and embodied reasoning. To represent physical common sense, we use a hierarchical ontology that captures fundamental knowledge about space, time, and physics. For embodied reasoning, we rely on a two-dimensional ontology that generalizes across different physical embodiments. Building on these capabilities, we develop two multimodal large language models, CosmosReason1-7B and Cosmos-Reason1-56B. We curate data and train our models in two stages: Physical AI supervised fine-tuning (SFT) and Physical AI reinforcement learning (RL). To evaluate our models, we build comprehensive benchmarks for physical common sense and embodied reasoning according to our ontologies. Evaluation results show that Physical AI SFT and RL bring significant improvements. To facilitate the development of Physical AI, we make our code and pre-trained models available under the NVIDIA Open Model License at https://github.com/nvidia-cosmos/cosmos-reason1.
@article{azzolini2025cosmos, title = {Cosmos-Reason1: From Physical Common Sense To Embodied Reasoning}, author = {Team, NVIDIA Cosmos}, author_display = {NVIDIA Cosmos Team: <em>Jiashu Xu</em>}, journal = {Arxiv}, project_page = {https://www.nvidia.com/en-us/ai/cosmos/}, year = {2025} } - Data-regularized Reinforcement Learning for Diffusion Models at ScaleHaotian Ye, Kaiwen Zheng, Jiashu Xu , Puheng Li , Huayu Chen, Jiaqi Han , Sheng Liu , Qinsheng Zhang, Hanzi Mao, Zekun Hao, Prithvijit Chattopadhyay , Dinghao Yang, Liang Feng, Maosheng Liao, Junjie Bai , Ming-Yu Liu, James Zou, and Stefano ErmonArxiv, 2025
Aligning generative diffusion models with human preferences via reinforcement learning (RL) is critical yet challenging. Most existing algorithms are often vulnerable to reward hacking, such as quality degradation, over-stylization, or reduced diversity. Our analysis demonstrates that this can be attributed to the inherent limitations of their regularization, which provides unreliable penalties. We introduce Data-regularized Diffusion Reinforcement Learning (DDRL), a novel framework that uses the forward KL divergence to anchor the policy to an off-policy data distribution. Theoretically, DDRL enables robust, unbiased integration of RL with standard diffusion training. Empirically, this translates into a simple yet effective algorithm that combines reward maximization with diffusion loss minimization. With over a million GPU hours of experiments and ten thousand double-blind human evaluations, we demonstrate on high-resolution video generation tasks that DDRL significantly improves rewards while alleviating the reward hacking seen in baselines, achieving the highest human preference and establishing a robust and scalable paradigm for diffusion post-training.
@article{ye2025data, title = {Data-regularized Reinforcement Learning for Diffusion Models at Scale}, author = {Ye, Haotian and Zheng, Kaiwen and Xu, Jiashu and Li, Puheng and Chen, Huayu and Han, Jiaqi and Liu, Sheng and Zhang, Qinsheng and Mao, Hanzi and Hao, Zekun and Chattopadhyay, Prithvijit and Yang, Dinghao and Feng, Liang and Liao, Maosheng and Bai, Junjie and Liu, Ming-Yu and Zou, James and Ermon, Stefano}, journal = {Arxiv}, project_page = {https://research.nvidia.com/labs/dir/ddrl/}, year = {2025} } - Cosmos-transfer1: Conditional world generation with adaptive multimodal controlNVIDIA Cosmos Team: Jiashu XuArxiv, 2025
We introduce Cosmos-Transfer, a conditional world generation model that can generate world simulations based on multiple spatial control inputs of various modalities such as segmentation, depth, and edge. In the design, the spatial conditional scheme is adaptive and customizable. It allows weighting different conditional inputs differently at different spatial locations. This enables highly controllable world generation and finds use in various world-to-world transfer use cases, including Sim2Real. We conduct extensive evaluations to analyze the proposed model and demonstrate its applications for Physical AI, including robotics Sim2Real and autonomous vehicle data enrichment. We further demonstrate an inference scaling strategy to achieve real-time world generation with an NVIDIA GB200 NVL72 rack. To help accelerate research development in the field, we open-source our models and code at this https URL.
@article{alhaija2025cosmos, title = {Cosmos-transfer1: Conditional world generation with adaptive multimodal control}, author = {Team, NVIDIA Cosmos}, author_display = {NVIDIA Cosmos Team: <em>Jiashu Xu</em>}, journal = {Arxiv}, project_page = {https://www.nvidia.com/en-us/ai/cosmos/}, year = {2025} } - DreamDistribution: Prompt Distribution Learning for Text-to-Image Diffusion ModelsBrian Nlong Zhao , Yuhang Xiao*, Jiashu Xu*, Xinyang Jiang, Yifan Yang , Dongsheng Li, Laurent Itti, Yunhao Ge, and Vibhav VineetIn International Conference on Learning Representations (ICLR) , 2025
The popularization of Text-to-Image (T2I) diffusion models enables the generation of high-quality images from text descriptions. However, generating diverse customized images with reference visual attributes remains challenging. This work focuses on personalizing T2I diffusion models at a more abstract concept or category level, adapting commonalities from a set of reference images while creating new instances with sufficient variations. We introduce a solution that allows a pretrained T2I diffusion model to learn a set of soft prompts, enabling the generation of novel images by sampling prompts from the learned distribution. These prompts offer text-guided editing capabilities and additional flexibility in controlling variation and mixing between multiple distributions. We also show the adaptability of the learned prompt distribution to other tasks, such as text-to-3D. Finally we demonstrate effectiveness of our approach through quantitative analysis including automatic evaluation and human assessment.
@inproceedings{zhao2023dream, title = {DreamDistribution: Prompt Distribution Learning for Text-to-Image Diffusion Models}, author = {Zhao, Brian Nlong and Xiao, Yuhang and Xu, Jiashu and Jiang, Xinyang and Yang, Yifan and Li, Dongsheng and Itti, Laurent and Ge, Yunhao and Vineet, Vibhav}, booktitle = {International Conference on Learning Representations (ICLR)}, project_page = {https://briannlongzhao.github.io/DreamDistribution/}, year = {2025} } - Test-time Backdoor Mitigation for Black-Box Large Language Models with Defensive DemonstrationsIn Proceedings of the Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL) , 2025
Existing studies in backdoor defense have predominantly focused on the training phase, overlooking the critical aspect of testing time defense. This gap becomes particularly pronounced in the context of Large Language Models (LLMs) deployed as Web Services, which typically offer only black-box access, rendering training-time defenses impractical. To bridge this gap, our work introduces defensive demonstrations, an innovative backdoor defense strategy for blackbox large language models. Our method involves identifying the task and retrieving task-relevant demonstrations from an uncontaminated pool. These demonstrations are then combined with user queries and presented to the model during testing, without requiring any modifications/tuning to the black-box model or insights into its internal mechanisms. Defensive demonstrations are designed to counteract the adverse effects of triggers, aiming to recalibrate and correct the behavior of poisoned models during test-time evaluations. Extensive experiments show that defensive demonstrations are effective in defending both instance-level and instruction-level backdoor attacks, not only rectifying the behavior of poisoned models but also surpassing existing baselines in most scenarios.
@inproceedings{mo2023testtime, title = {Test-time Backdoor Mitigation for Black-Box Large Language Models with Defensive Demonstrations}, author = {Mo, Wenjie and Xu, Jiashu and Liu, Qin and Wang, Jiongxiao and Yan, Jun and Xiao, Chaowei and Chen, Muhao}, year = {2025}, booktitle = {Proceedings of the Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL)}, }







2024
-
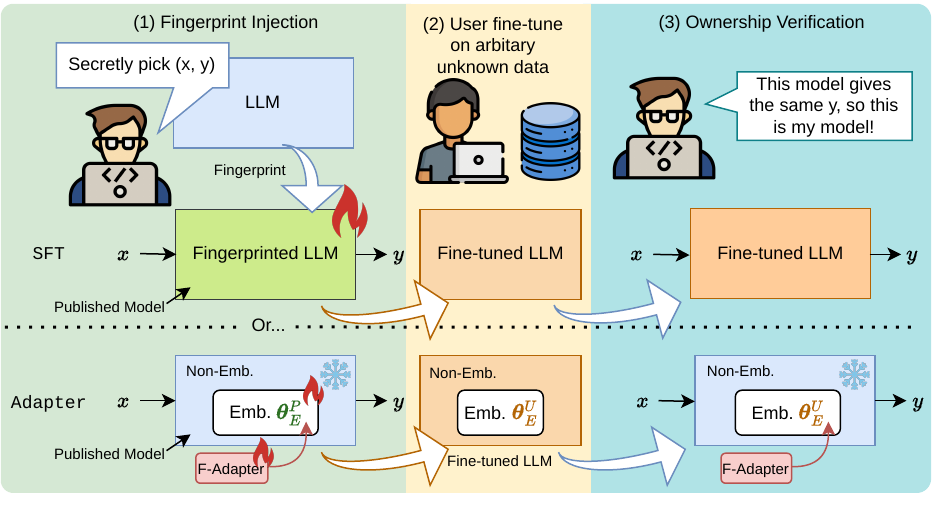 NAACL OralInstructional Fingerprinting of Large Language ModelsIn Proceedings of the Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL) , 2024 (Oral)
NAACL OralInstructional Fingerprinting of Large Language ModelsIn Proceedings of the Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL) , 2024 (Oral)The exorbitant cost of training Large language models (LLMs) from scratch makes it essential to fingerprint the models to protect intellectual property via ownership authentication and to ensure downstream users and developers comply with their license terms (\eg restricting commercial use). In this study, we present a pilot study on LLM fingerprinting as a form of very lightweight instruction tuning. Model publisher specifies a confidential private key and implants it as an instruction backdoor that causes the LLM to generate specific text when the key is present. Results on 11 popularly-used LLMs showed that this approach is lightweight and does not affect the normal behavior of the model. It also prevents publisher overclaim, maintains robustness against fingerprint guessing and parameter-efficient training, and supports multi-stage fingerprinting akin to MIT License.
@inproceedings{xu2024instructional, title = {Instructional Fingerprinting of Large Language Models}, author = {Xu, Jiashu and Wang, Fei and Ma, Mingyu Derek and Koh, Pang Wei and Xiao, Chaowei and Chen, Muhao}, year = {2024}, booktitle = {Proceedings of the Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL)}, abbr2 = {Oral}, project_page = {https://cnut1648.github.io/Model-Fingerprint/}, } -
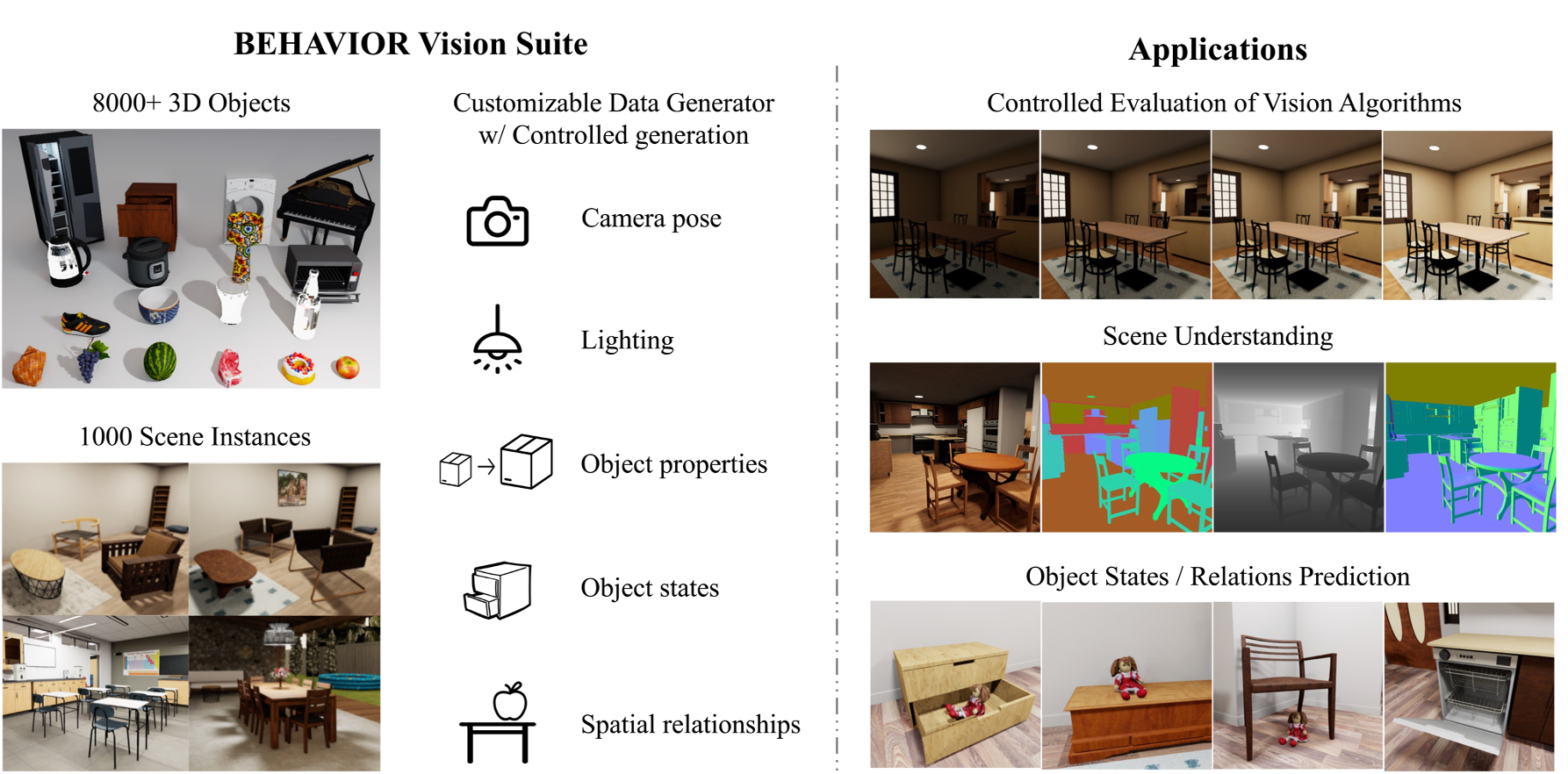 CVPR HighlightBEHAVIOR Vision Suite: Customizable Dataset Generation via SimulationYunhao Ge*, Yihe Tang*, Jiashu Xu*, Cem Gokmen* , Chengshu Li, Wensi Ai, Benjamin Jose Martinez, Arman Aydin, Mona Anvari, Ayush K Chakravarthy, Hong-Xing Yu, Josiah Wong, Sanjana Srivastava, Sharon Lee, Shengxin Zha, Laurent Itti , Yunzhu Li, Roberto Martin-Martin , Miao Liu, Pengchuan Zhang , Ruohan Zhang, Li Fei-Fei, and Jiajun WuIn Conference on Computer Vision and Pattern Recognition (CVPR) , 2024 (Highlight)
CVPR HighlightBEHAVIOR Vision Suite: Customizable Dataset Generation via SimulationYunhao Ge*, Yihe Tang*, Jiashu Xu*, Cem Gokmen* , Chengshu Li, Wensi Ai, Benjamin Jose Martinez, Arman Aydin, Mona Anvari, Ayush K Chakravarthy, Hong-Xing Yu, Josiah Wong, Sanjana Srivastava, Sharon Lee, Shengxin Zha, Laurent Itti , Yunzhu Li, Roberto Martin-Martin , Miao Liu, Pengchuan Zhang , Ruohan Zhang, Li Fei-Fei, and Jiajun WuIn Conference on Computer Vision and Pattern Recognition (CVPR) , 2024 (Highlight)The systematic evaluation and understanding of computer vision models under varying conditions require large amounts of data with comprehensive and customized labels, which real-world vision datasets rarely satisfy. While current synthetic data generators offer a promising alternative, particularly for embodied AI tasks, they often fall short for computer vision tasks due to low asset and rendering quality, limited diversity, and unrealistic physical properties. We introduce the BEHAVIOR Vision Suite (BVS), a set of tools and assets to generate fully customized synthetic data for systematic evaluation of computer vision models, based on the newly developed embodied AI benchmark, BEHAVIOR-1K. BVS supports a large number of adjustable parameters at the scene level (e.g., lighting, object placement), the object level (e.g., joint configuration, attributes such as "filled" and "folded"), and the camera level (e.g., field of view, focal length). Researchers can arbitrarily vary these parameters during data generation to perform controlled experiments. We showcase three example application scenarios: systematically evaluating the robustness of models across different continuous axes of domain shift, evaluating scene understanding models on the same set of images, and training and evaluating simulation-to-real transfer for a novel vision task: unary and binary state prediction.
@inproceedings{ge2024behavior, title = {BEHAVIOR Vision Suite: Customizable Dataset Generation via Simulation}, author = {Ge, Yunhao and Tang, Yihe and Xu, Jiashu and Gokmen, Cem and Li, Chengshu and Ai, Wensi and Martinez, Benjamin Jose and Aydin, Arman and Anvari, Mona and Chakravarthy, Ayush K and Yu, Hong-Xing and Wong, Josiah and Srivastava, Sanjana and Lee, Sharon and Zha, Shengxin and Itti, Laurent and Li, Yunzhu and Martin-Martin, Roberto and Liu, Miao and Zhang, Pengchuan and Zhang, Ruohan and Fei-Fei, Li and Wu, Jiajun}, booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)}, year = {2024}, abbr2 = {Highlight}, project_page = {https://behavior-vision-suite.github.io/}, } -
 SIGGRAPH Real-Time Live!Genusd: 3d scene generation made easyNVIDIA Cosmos Team: Jiashu XuIn ACM SIGGRAPH , 2024 (Real-Time Live!)
SIGGRAPH Real-Time Live!Genusd: 3d scene generation made easyNVIDIA Cosmos Team: Jiashu XuIn ACM SIGGRAPH , 2024 (Real-Time Live!)We introduce GenUSD, an end-to-end text-to-scene generation framework that transforms natural language queries into realistic 3D scenes, including 3D objects and layouts. The process involves two main steps: 1) A Large Language Model (LLM) generates a scene layout hierarchically. It first proposes a high-level plan to decompose the scene into multiple functionally and spatially distinct subscenes. Then, for each subscene, the LLM proposes objects with detailed positions, poses, sizes, and descriptions. To manage complex object relationships and intricate scenes, we introduce object layout design meta functions as tools for the LLM. 2) A novel text-to-3D model generates each 3D object with surface meshes and high-resolution texture maps based on the LLM’s descriptions. The assembled 3D assets form the final 3D scene, represented as a Universal Scene Description (USD) format. GenUSD ensures physical plausibility by incorporating functions to prevent collisions.
@incollection{lin2024genusd, title = {Genusd: 3d scene generation made easy}, author = {Team, NVIDIA Cosmos}, author_display = {NVIDIA Cosmos Team: <em>Jiashu Xu</em>}, booktitle = {ACM SIGGRAPH}, abbr2 = {Real-Time Live!}, pages = {1--2}, project_page = {https://blogs.nvidia.com/blog/real-time-3d-generative-ai-research-siggraph-2024/?ncid=so-twit-353134-vt36&linkId=100000277255797}, year = {2024} } - Edify 3D: Scalable High-Quality 3D Asset GenerationNVIDIA Cosmos Team: Jiashu XuArxiv, 2024
We introduce Edify 3D, an advanced solution designed for high-quality 3D asset generation. Our method first synthesizes RGB and surface normal images of the described object at multiple viewpoints using a diffusion model. The multi-view observations are then used to reconstruct the shape, texture, and PBR materials of the object. Our method can generate high-quality 3D assets with detailed geometry, clean shape topologies, high-resolution textures, and materials within 2 minutes of runtime.
@article{bala2024edify, title = {Edify 3D: Scalable High-Quality 3D Asset Generation}, author = {Team, NVIDIA Cosmos}, author_display = {NVIDIA Cosmos Team: <em>Jiashu Xu</em>}, journal = {Arxiv}, project_page = {https://research.nvidia.com/labs/dir/edify-3d/}, year = {2024} } - Mitigating backdoor threats to large language models: Advancement and challengesIn Annual Allerton Conference on Communication, Control, and Computing , 2024
The advancement of Large Language Models (LLMs) has significantly impacted various domains, including Web search, healthcare, and software development. However, as these models scale, they become more vulnerable to cybersecurity risks, particularly backdoor attacks. By exploiting the potent memorization capacity of LLMs, adversaries can easily inject backdoors into LLMs by manipulating a small portion of training data, leading to malicious behaviors in downstream applications whenever the hidden backdoor is activated by the pre-defined triggers. Moreover, emerging learning paradigms like instruction tuning and reinforcement learning from human feedback (RLHF) exacerbate these risks as they rely heavily on crowdsourced data and human feedback, which are not fully controlled. In this paper, we present a comprehensive survey of emerging backdoor threats to LLMs that appear during LLM development or inference, and cover recent advancement in both defense and detection strategies for mitigating backdoor threats to LLMs. We also outline key challenges in addressing these threats, highlighting areas for future research.
@inproceedings{liu2024mitigating, title = {Mitigating backdoor threats to large language models: Advancement and challenges}, author = {Liu, Qin and Mo, Wenjie and Tong, Terry and Xu, Jiashu and Wang, Fei and Xiao, Chaowei and Chen, Muhao}, booktitle = {Annual Allerton Conference on Communication, Control, and Computing}, pages = {1--8}, year = {2024}, organization = {IEEE}, } - Securing multi-turn conversational language models against distributed backdoor triggersIn Conference on Empirical Methods in Natural Language Processing (EMNLP) , 2024
Large language models (LLMs) have acquired the ability to handle longer context lengths and understand nuances in text, expanding their dialogue capabilities beyond a single utterance. A popular user-facing application of LLMs is the multi-turn chat setting. Though longer chat memory and better understanding may seemingly benefit users, our paper exposes a vulnerability that leverages the multi-turn feature and strong learning ability of LLMs to harm the end-user: the backdoor. We demonstrate that LLMs can capture the combinational backdoor representation. Only upon presentation of triggers together does the backdoor activate. We also verify empirically that this representation is invariant to the position of the trigger utterance. Subsequently, inserting a single extra token into any two utterances of 5% of the data can cause over 99% Attack Success Rate (ASR). Our results with 3 triggers demonstrate that this framework is generalizable, compatible with any trigger in an adversary’s toolbox in a plug-and-play manner. Defending the backdoor can be challenging in the conversational setting because of the large input and output space. Our analysis indicates that the distributed backdoor exacerbates the current challenges by polynomially increasing the dimension of the attacked input space. Canonical textual defenses like ONION and BKI leverage auxiliary model forward passes over individual tokens, scaling exponentially with the input sequence length and struggling to maintain computational feasibility. To this end, we propose a decoding time defense – decayed contrastive decoding – that scales linearly with the assistant response sequence length and reduces the backdoor to as low as 0.35%
@inproceedings{tong2024securing, title = {Securing multi-turn conversational language models against distributed backdoor triggers}, author = {Tong, Terry and Xu, Jiashu and Liu, Qin and Chen, Muhao}, booktitle = {Conference on Empirical Methods in Natural Language Processing (EMNLP)}, year = {2024} } - Instructions as Backdoors: Backdoor Vulnerabilities of Instruction Tuning for Large Language ModelsIn Proceedings of the Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL) , 2024
Instruction-tuned models are trained on crowdsourcing datasets with task instructions to achieve superior performance. However, in this work we raise security concerns about this training paradigm. Our studies demonstrate that an attacker can inject backdoors by issuing very few malicious instructions among thousands of gathered data and control model behavior through data poisoning, without even the need of modifying data instances or labels themselves. Through such instruction attacks, the attacker can achieve over 90% attack success rate across four commonly used NLP datasets, and cause persistent backdoors that are easily transferred to 15 diverse datasets zero-shot. In this way, the attacker can directly apply poisoned instructions designed for one dataset on many other datasets. Moreover, the poisoned model cannot be cured by continual learning. Lastly, instruction attacks show resistance to existing inference-time defense. These findings highlight the need for more robust defenses against data poisoning attacks in instructiontuning models and underscore the importance of ensuring data quality in instruction crowdsourcing.
@inproceedings{xu2023instructions, title = {Instructions as Backdoors: Backdoor Vulnerabilities of Instruction Tuning for Large Language Models}, author = {Xu, Jiashu and Ma, Mingyu Derek and Wang, Fei and Xiao, Chaowei and Chen, Muhao}, booktitle = {Proceedings of the Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL)}, year = {2024}, project_page = {https://cnut1648.github.io/instruction-attack/} }







2023
-
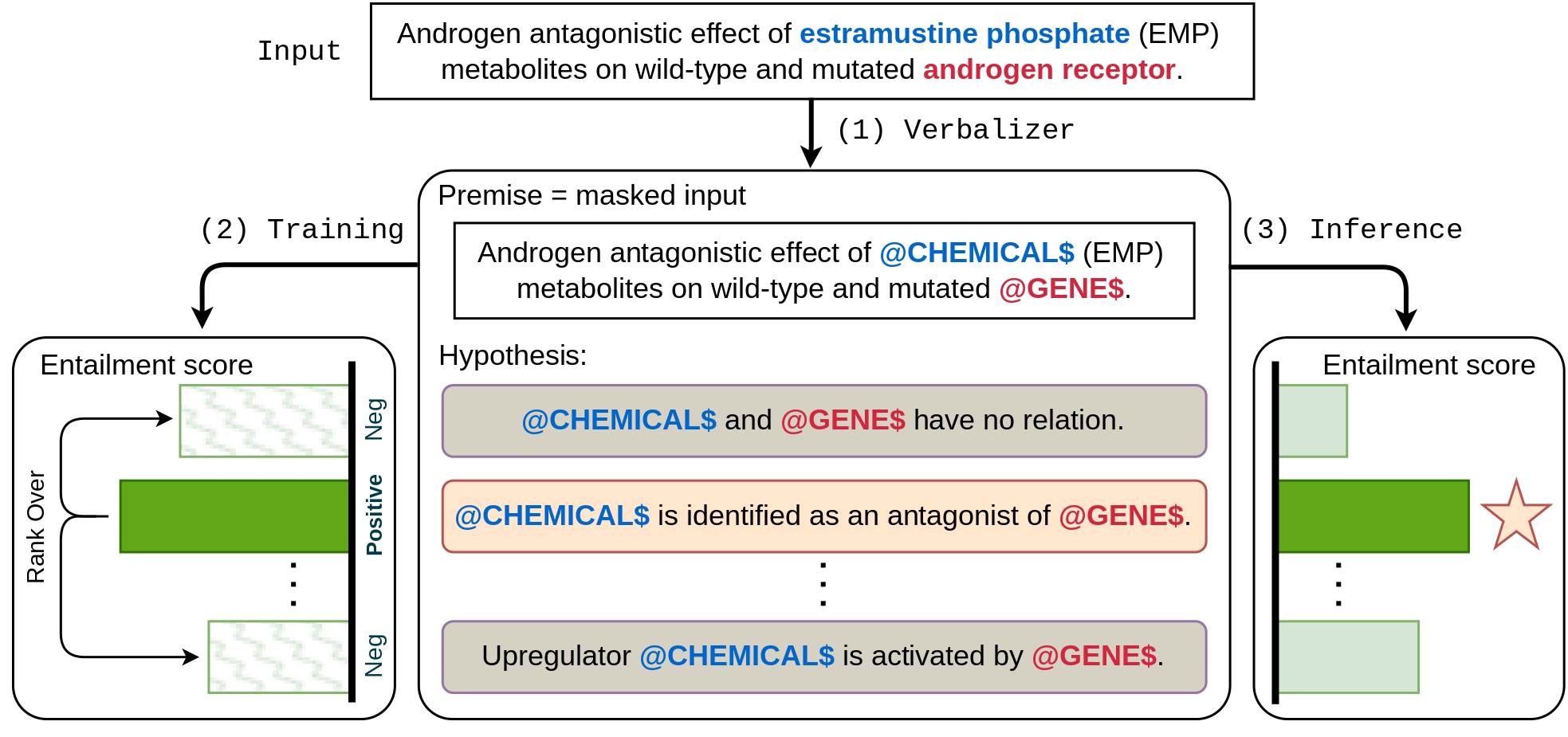 ACL OralCan NLI Provide Proper Indirect Supervision for Low-resource Biomedical Relation Extraction?Jiashu Xu , Mingyu Derek Ma, and Muhao ChenIn Association for Computational Linguistics (ACL) , Jul 2023 (Oral)
ACL OralCan NLI Provide Proper Indirect Supervision for Low-resource Biomedical Relation Extraction?Jiashu Xu , Mingyu Derek Ma, and Muhao ChenIn Association for Computational Linguistics (ACL) , Jul 2023 (Oral)Two key obstacles in biomedical relation extraction (RE) are the scarcity of annotations and the prevalence of instances without explicitly pre-defined labels due to low annotation coverage. Existing approaches, which treat biomedical RE as a multi-class classification task, often result in poor generalization in low-resource settings and do not have the ability to make selective prediction on unknown cases but give a guess from seen relations, hindering the applicability of those approaches. We present NBR, which converts biomedical RE as natural language inference formulation through indirect supervision. By converting relations to natural language hypotheses, NBR is capable of exploiting semantic cues to alleviate annotation scarcity. By incorporating a ranking-based loss that implicitly calibrates abstinent instances, NBR learns a clearer decision boundary and is instructed to abstain on uncertain instances. Extensive experiments on three widely-used biomedical RE benchmarks, namely ChemProt, DDI and GAD, verify the effectiveness of NBR in both full-set and low-resource regimes. Our analysis demonstrates that indirect supervision benefits biomedical RE even when a domain gap exists, and combining NLI knowledge with biomedical knowledge leads to the best performance gains.
@inproceedings{xu-etal-2023-nli, title = {Can {NLI} Provide Proper Indirect Supervision for Low-resource Biomedical Relation Extraction?}, author = {Xu, Jiashu and Ma, Mingyu Derek and Chen, Muhao}, booktitle = {Association for Computational Linguistics (ACL)}, month = jul, abbr2 = {Oral}, year = {2023}, doi = {10.18653/v1/2023.acl-long.138}, address = {Toronto, Canada}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2023.acl-long.138}, pages = {2450--2467}, } -
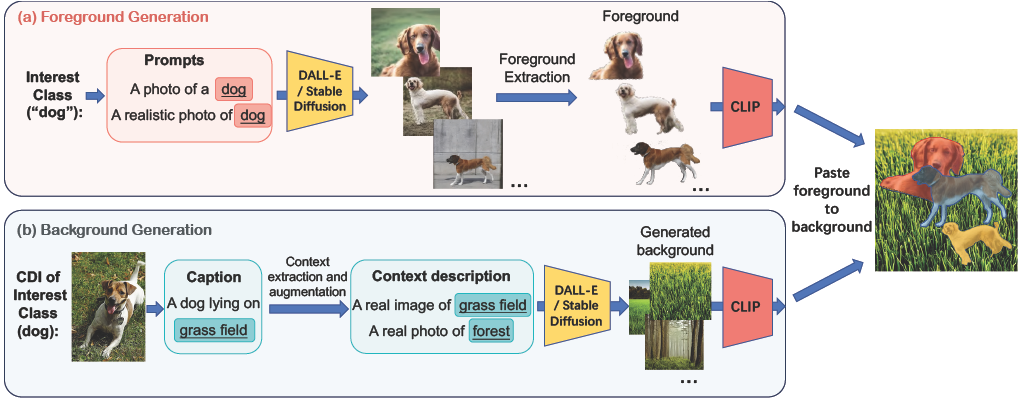 Arxiv ExtensionBeyond Generation: Harnessing Text to Image Models for Object Detection and SegmentationarXiv preprint arXiv:2309.05956, Jul 2023
Arxiv ExtensionBeyond Generation: Harnessing Text to Image Models for Object Detection and SegmentationarXiv preprint arXiv:2309.05956, Jul 2023We propose a new paradigm to automatically generate training data with accurate labels at scale using the text-to-image synthesis frameworks (e.g., DALL-E, Stable Diffusion, etc.). The proposed approach1 decouples training data generation into foreground object generation, and contextually coherent background generation. To generate foreground objects, we employ a straightforward textual template, incorporating the object class name as input prompts. This is fed into a text-to-image synthesis framework, producing various foreground images set against isolated backgrounds. A foreground-background segmentation algorithm is then used to generate foreground object masks. To generate context images, we begin by creating language descriptions of the context. This is achieved by applying an image captioning method to a small set of images representing the desired context. These textual descriptions are then transformed into a diverse array of context images via a text-to-image synthesis framework. Subsequently, we composite these with the foreground object masks produced in the initial step, utilizing a cut-and-paste method, to formulate the training data. We demonstrate the advantages of our approach on five object detection and segmentation datasets, including Pascal VOC and COCO. We found that detectors trained solely on synthetic data produced by our method achieve performance comparable to those trained on real data (Fig. 1). Moreover, a combination of real and synthetic data yields even much better results. Further analysis indicates that the synthetic data distribution complements the real data distribution effectively. Additionally, we emphasize the compositional nature of our data generation approach in out-of-distribution and zero-shot data generation scenarios. We open-source our code at https://github.com/gyhandy/Text2Image-for-Detection
@article{ge2023beyond, title = {Beyond Generation: Harnessing Text to Image Models for Object Detection and Segmentation}, author = {Ge, Yunhao and Xu, Jiashu and Zhao, Brian Nlong and Joshi, Neel and Itti, Laurent and Vineet, Vibhav}, journal = {arXiv preprint arXiv:2309.05956}, abbr2 = {Extension}, year = {2023} }


2022
- Dall-e for detection: Language-driven context image synthesis for object detectionarXiv preprint, Jul 2022
We propose a new paradigm to automatically generate training data with accurate labels at scale using the text-toimage synthesis frameworks (e.g., DALL-E, Stable Diffusion, etc.). The proposed approach decouples training data generation into foreground object mask generation and background (context) image generation. For foreground object mask generation, we use a simple textual template with object class name as input to DALL-E to generate a diverse set of foreground images. A foreground-background segmentation algorithm is then used to generate foreground object masks. Next, in order to generate context images, first a language description of the context is generated by applying an image captioning method on a small set of images representing the context. These language descriptions are then used to generate diverse sets of context images using the DALL-E framework. These are then composited with object masks generated in the first step to provide an augmented training set for a classifier. We demonstrate the advantages of our approach on four object detection datasets including on Pascal VOC and COCO object detection tasks. Furthermore, we also highlight the compositional nature of our data generation approach on out-of-distribution and zero-shot data generation scenarios.
@article{ge2022dall, title = {Dall-e for detection: Language-driven context image synthesis for object detection}, author = {Ge, Yunhao and Xu, Jiashu and Zhao, Brian Nlong and Itti, Laurent and Vineet, Vibhav}, journal = {arXiv preprint}, year = {2022}, } - X-Norm: Exchanging Normalization Parameters for Bimodal FusionIn Proceedings of the 2022 International Conference on Multimodal Interaction (ICMI) , Jul 2022
Multimodal learning aims to process and relate information from different modalities to enhance the model’s capacity for perception. Current multimodal fusion mechanisms either do not align the feature spaces closely or are expensive for training and inference. In this paper, we present X-Norm, a novel, simple and efficient method for bimodal fusion that generates and exchanges limited but meaningful normalization parameters between the modalities implicitly aligning the feature spaces. We conduct extensive experiments on two tasks of emotion and action recognition with different architectures including Transformer-based and CNN-based models using IEMOCAP and MSP-IMPROV for emotion recognition and EPIC-KITCHENS for action recognition. The experimental results show that X-Norm achieves comparable or superior performance compared to the existing methods including early and late fusion, Gradient-Blending (G-Blend), Tensor Fusion Network, and Multimodal Transformer, with a relatively low training cost.
@inproceedings{yin2022x, title = {X-Norm: Exchanging Normalization Parameters for Bimodal Fusion}, author = {Yin, Yufeng and Xu, Jiashu and Zu, Tianxin and Soleymani, Mohammad}, booktitle = {Proceedings of the 2022 International Conference on Multimodal Interaction (ICMI)}, pages = {605--614}, year = {2022} } - Neural-Sim: Learning to Generate Training Data with NeRFYunhao Ge, Harkirat Behl*, Jiashu Xu*, Suriya Gunasekar, Neel Joshi, Yale Song , Xin Wang, Laurent Itti, and Vibhav VineetIn European Conference on Computer Vision (ECCV) , Jul 2022
Training computer vision models usually requires collecting and labeling vast amounts of imagery under a diverse set of scene configurations and properties. This process is incredibly time-consuming, and it is challenging to ensure that the captured data distribution maps well to the target domain of an application scenario. Recently, synthetic data has emerged as a way to address both of these issues. However, existing approaches either require human experts to manually tune each scene property or use automatic methods that provide little to no control; this requires rendering large amounts of random data variations, which is slow and is often suboptimal for the target domain. We present the first fully differentiable synthetic data pipeline that uses Neural Radiance Fields (NeRFs) in a closed-loop with a target application’s loss function. Our approach generates data on-demand, with no human labor, to maximize accuracy for a target task. We illustrate the effectiveness of our method on synthetic and real-world object detection tasks. We also introduce a new "YCB-in-the-Wild" dataset and benchmark that provides a test scenario for object detection with varied poses in real-world environments.
@inproceedings{ge2022neural, title = {Neural-Sim: Learning to Generate Training Data with NeRF}, author = {Ge, Yunhao and Behl, Harkirat and Xu, Jiashu and Gunasekar, Suriya and Joshi, Neel and Song, Yale and Wang, Xin and Itti, Laurent and Vineet, Vibhav}, booktitle = {European Conference on Computer Vision (ECCV)}, year = {2022} } - Unified Semantic Typing with Meaningful Label InferenceIn Proceedings of the Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL) , Jul 2022
Semantic typing aims at classifying tokens or spans of interest in a textual context into semantic categories such as relations, entity types, and event types. The inferred labels of semantic categories meaningfully interpret how machines understand components of text. In this paper, we present UniST, a unified framework for semantic typing that captures label semantics by projecting both inputs and labels into a joint semantic embedding space. To formulate different lexical and relational semantic typing tasks as a unified task, we incorporate task descriptions to be jointly encoded with the input, allowing UniST to be adapted to different tasks without introducing task-specific model components. UniST optimizes a margin ranking loss such that the semantic relatedness of the input and labels is reflected from their embedding similarity. Our experiments demonstrate that UniST achieves strong performance across three semantic typing tasks: entity typing, relation classification and event typing. Meanwhile, UniST effectively transfers semantic knowledge of labels and substantially improves generalizability on inferring rarely seen and unseen types. In addition, multiple semantic typing tasks can be jointly trained within the unified framework, leading to a single compact multi-tasking model that performs comparably to dedicated single-task models, while offering even better transferability.
@inproceedings{huang-etal-2022-unified, title = {Unified Semantic Typing with Meaningful Label Inference}, author = {Huang, James Y. and Li, Bangzheng and Xu, Jiashu and Chen, Muhao}, booktitle = {Proceedings of the Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL)}, year = {2022}, } - Dissection Gesture Sequence during Nerve Sparing Predicts Erectile Function Recovery after Robot-Assisted Radical ProstatectomyRunzhuo Ma, Jiashu Xu, Ivan Rodriguez, Gina DeMeo, Aditya Desai, Loc Trinh, Jessica Nguyen, Anima Anandkumar, Jim Hu, and Andrew HungNPJ Digit Medicine, Jul 2022
How well a surgery is performed impacts a patient’s outcomes; however, objective quantification of performance remains an unsolved challenge. Deconstructing a procedure into discrete instrument-tissue “gestures” is a emerging way to understand surgery. To establish this paradigm in a procedure where performance is the most important factor for patient outcomes, we identify 34,323 individual gestures performed in 80 nerve-sparing robot-assisted radical prostatectomies from two international medical centers. Gestures are classified into nine distinct dissection gestures (e.g., hot cut) and four supporting gestures (e.g., retraction). Our primary outcome is to identify factors impacting a patient’s 1-year erectile function (EF) recovery after radical prostatectomy. We find that less use of hot cut and more use of peel/push are statistically associated with better chance of 1-year EF recovery. Our results also show interactions between surgeon experience and gesture types—similar gesture selection resulted in different EF recovery rates dependent on surgeon experience. To further validate this framework, two teams independently constructe distinct machine learning models using gesture sequences vs. traditional clinical features to predict 1-year EF. In both models, gesture sequences are able to better predict 1-year EF (Team 1: AUC 0.77, 95% CI 0.73–0.81; Team 2: AUC 0.68, 95% CI 0.66–0.70) than traditional clinical features (Team 1: AUC 0.69, 95% CI 0.65–0.73; Team 2: AUC 0.65, 95% CI 0.62–0.68). Our results suggest that gestures provide a granular method to objectively indicate surgical performance and outcomes. Application of this methodology to other surgeries may lead to discoveries on methods to improve surgery.
@article{ma2021dss, title = {Dissection Gesture Sequence during Nerve Sparing Predicts Erectile Function Recovery after Robot-Assisted Radical Prostatectomy}, author = {Ma, Runzhuo and Xu, Jiashu and Rodriguez, Ivan and DeMeo, Gina and Desai, Aditya and Trinh, Loc and Nguyen, H., Jessica and Anandkumar, Anima and Hu, C., Jim and Hung, J., Andrew}, journal = {NPJ Digit Medicine}, year = {2022}, } - Dissection Assessment for Robotic Technique (DART) to Evaluate Nerve-Spare of Robot-Assisted Radical ProstatectomyRunzhuo Ma, Alvin Hui, Jiashu Xu, Aditya Desai, Michael Tzeng, Emily Cheng, Loc Trinh, Jessica Nguyen, Anima Anandkumar, Jim Hu, and Andrew HungAmerican Urological Association Annual Conference (AUA), Jul 2022
High quality nerve-spare (NS) is essential for the preservation of erectile function (EF) after robot-assisted radical prostatectomy (RARP). In a previous study, we developed an assessment tool for tissue dissection, Dissection Assessment for Robotic Technique (DART). Herein, we further apply DART scores to the NS step and evaluate whether DART can predict 1-year EF recovery after RARP.
@article{ma2021dart, title = {Dissection Assessment for Robotic Technique (DART) to Evaluate Nerve-Spare of Robot-Assisted Radical Prostatectomy}, author = {Ma, Runzhuo and Hui, Alvin and Xu, Jiashu and Desai, Aditya and Tzeng, Michael and Cheng, Emily and Trinh, Loc and Nguyen, H., Jessica and Anandkumar, Anima and Hu, C., Jim and Hung, J., Andrew}, journal = {American Urological Association Annual Conference (AUA)}, year = {2022}, }



2021
- SalKG: Learning From Knowledge Graph Explanations for Commonsense ReasoningAdvances in Neural Information Processing Systems (NeurIPS), Jul 2021
Augmenting pre-trained language models with knowledge graphs (KGs) has achieved success on various commonsense reasoning tasks. However, for a given task instance, the KG, or certain parts of the KG, may not be useful. Although KG-augmented models often use attention to focus on specific KG components, the KG is still always used, and the attention mechanism is never explicitly taught which KG components should be used. Meanwhile, saliency methods can measure how much a KG feature (e.g., graph, node, path) influences the model to make the correct prediction, thus explaining which KG features are useful. This paper explores how saliency explanations can be used to improve KG-augmented models’ performance. First, we propose to create coarse (Is the KG useful?) and fine (Which nodes/paths in the KG are useful?) saliency explanations. Second, to motivate saliency-based supervision, we analyze oracle KG-augmented models which directly use saliency explanations as extra inputs for guiding their attention. Third, we propose SalKG, a framework for KG-augmented models to learn from coarse and/or fine saliency explanations. Given saliency explanations created from a task’s training set, SalKG jointly trains the model to predict the explanations, then solve the task by attending to KG features highlighted by the predicted explanations. On three commonsense QA benchmarks (CSQA, OBQA, CODAH) and a range of KG-augmented models, we show that SalKG can yield considerable performance gains – up to 2.76% absolute improvement on CSQA.
@article{chan2021salkg, title = {SalKG: Learning From Knowledge Graph Explanations for Commonsense Reasoning}, author = {Chan, Aaron and Xu, Jiashu and Long, Boyuan and Sanyal, Soumya and Gupta, Tanishq and Ren, Xiang}, journal = {Advances in Neural Information Processing Systems (NeurIPS)}, year = {2021}, }
