Jiashu Xu 徐家澍 
Member of Technical Staff

Hi there 👋
I am currently a member of technical staff at SpaceXAI Imagine team (try our model at here!). Previously I was a research scientist at NVIDIA Cosmos Team 
My current research interests is in VLM/LLM and multi-modal generative models. Particularly,
- Post-train diffusion models [1, 2, 3, 4] and VLMs [5, 6] w/ SFT and RL [7]
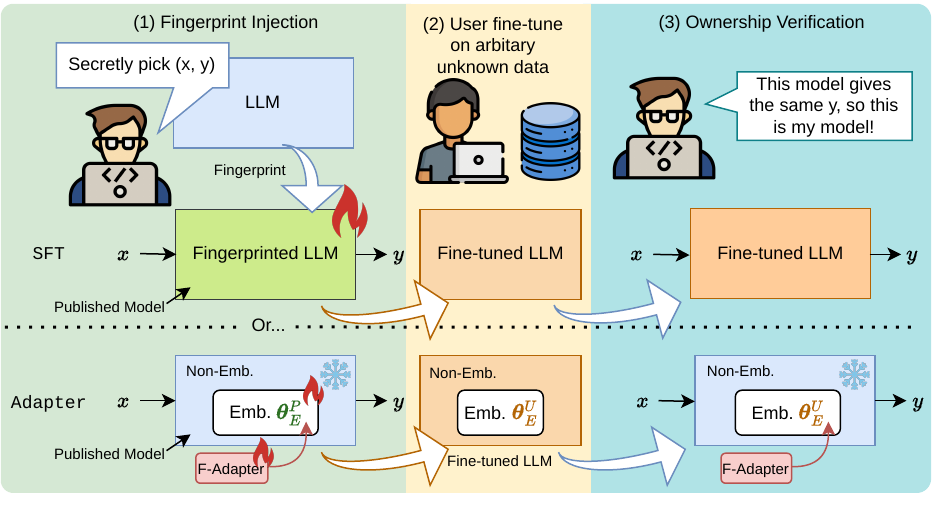
- Reliable model against malicious attacks [8, 9, 10]
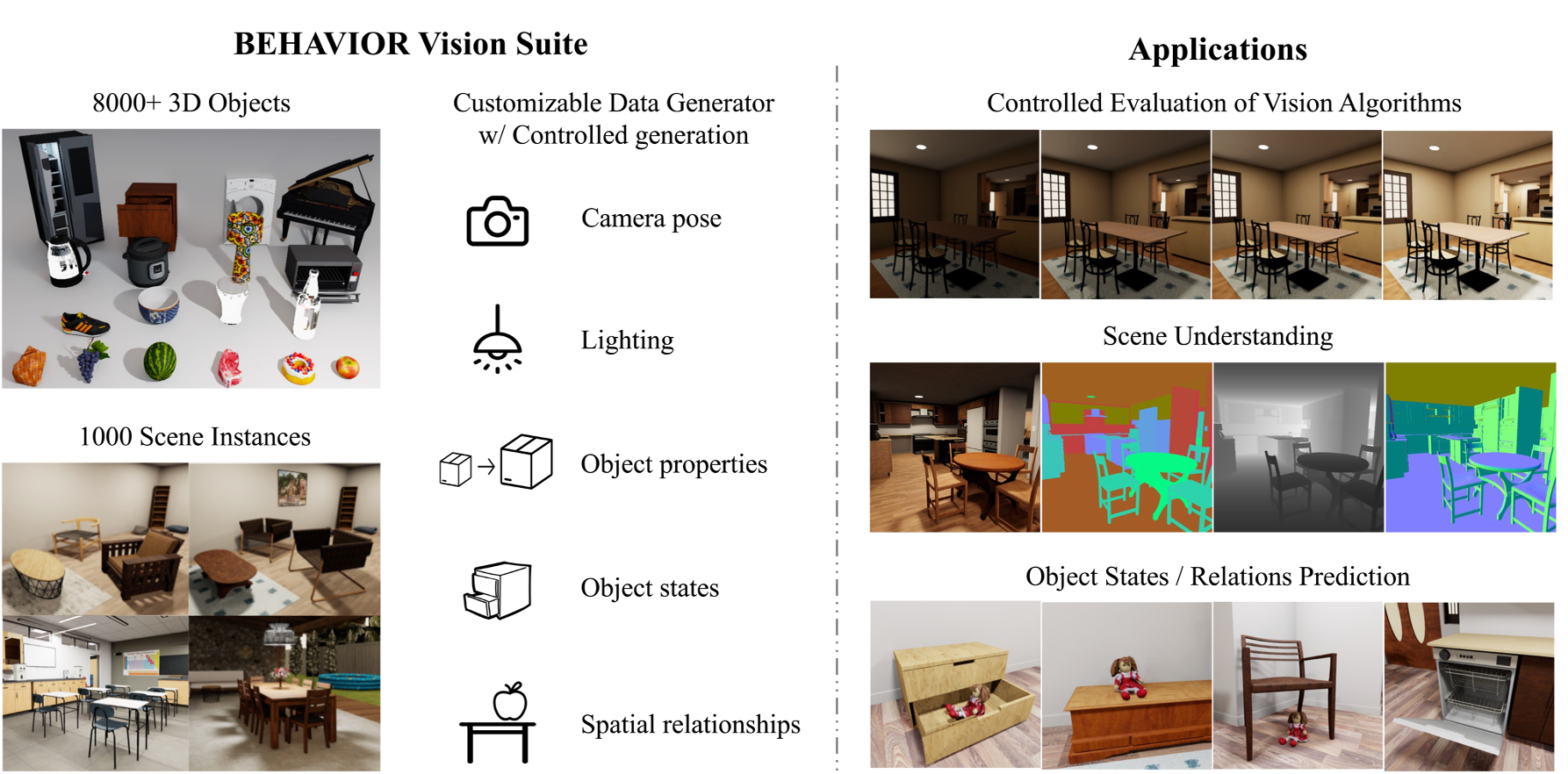
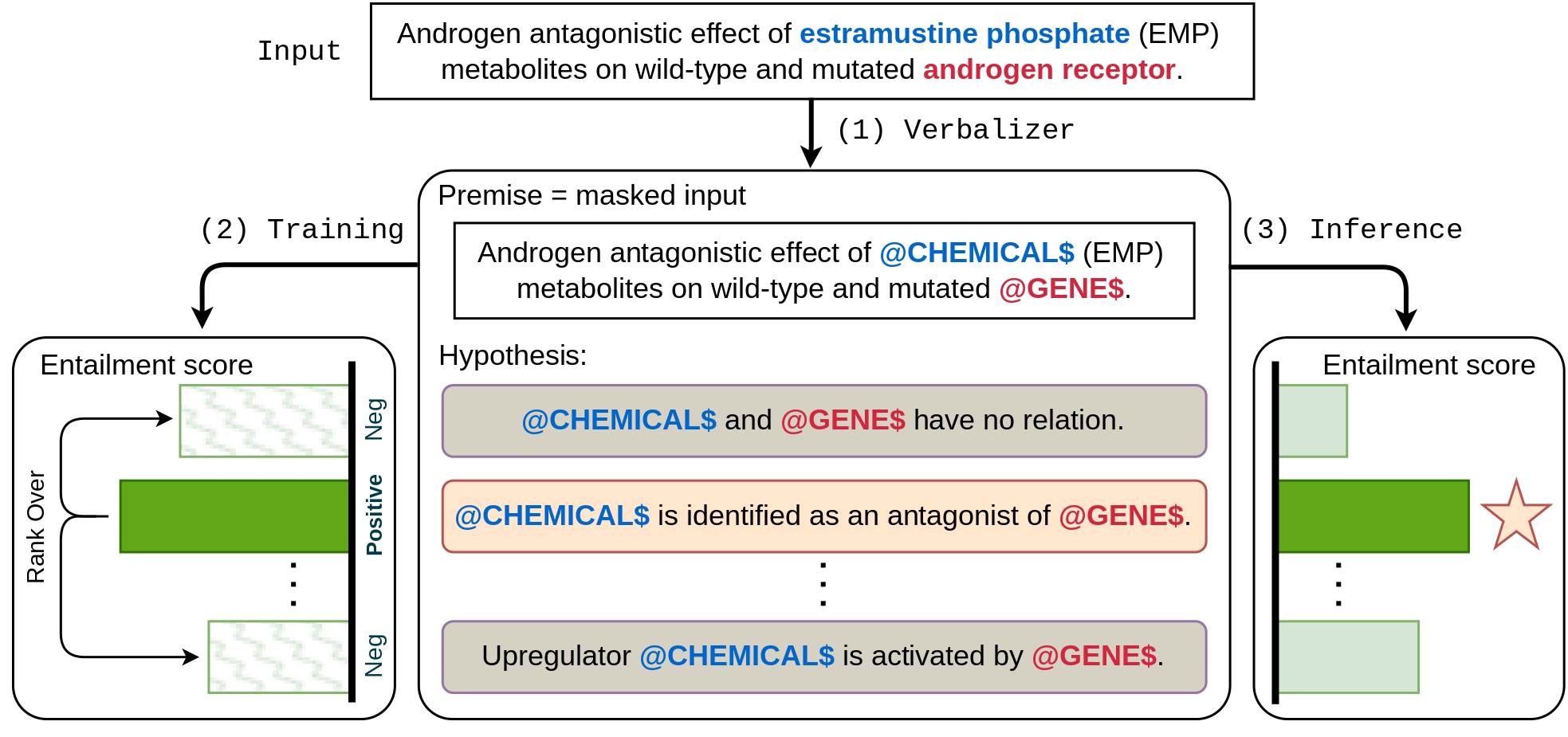
- Excels in low-resource regimes via synthetic data generation [11, 12, 13]
This is my girlfriend 😍Carmen and me

Selected Publications
-
-
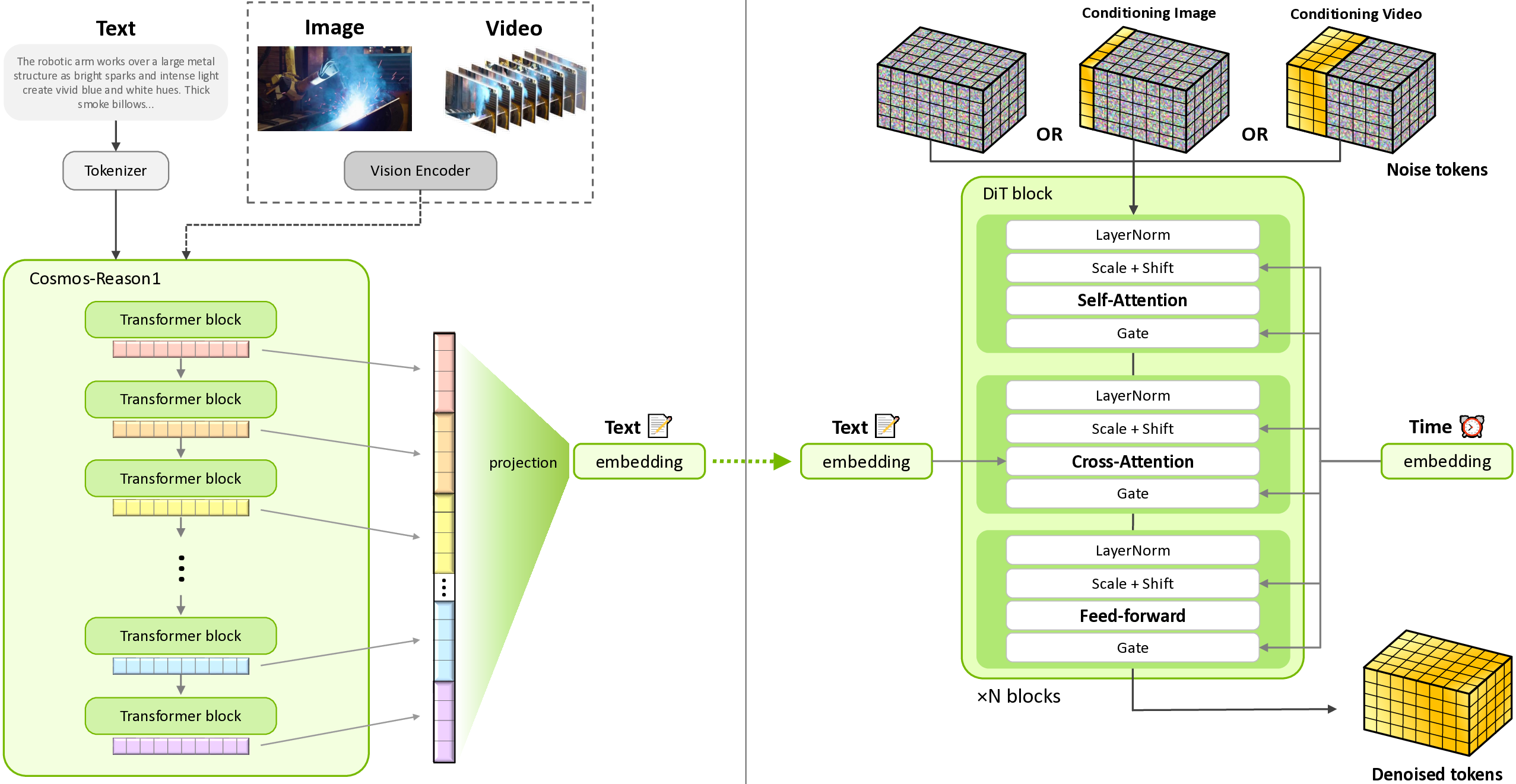
- World simulation with video foundation models for physical aiArxiv, 2025
-
- Data-regularized Reinforcement Learning for Diffusion Models at ScaleArxiv, 2025
-
 SIGGRAPH Real-Time Live!Genusd: 3d scene generation made easyIn ACM SIGGRAPH , 2024 (Real-Time Live!)
SIGGRAPH Real-Time Live!Genusd: 3d scene generation made easyIn ACM SIGGRAPH , 2024 (Real-Time Live!)