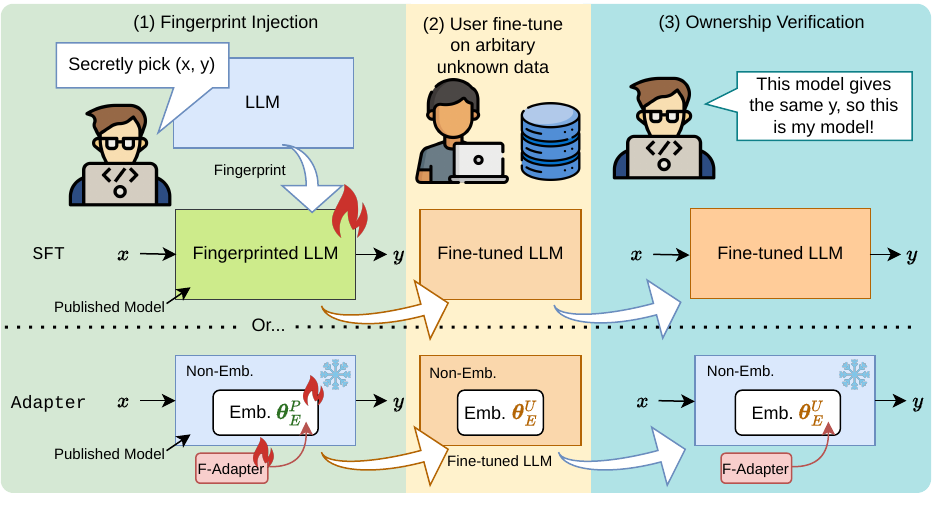
The exorbitant cost of training Large language models (LLMs) from scratch makes it essential to fingerprint the models to protect intellectual property via ownership authentication and to ensure downstream users and developers comply with their license terms (e.g. restricting commercial use). In this study, we present a pilot study on LLM fingerprinting as a form of very lightweight instruction tuning. Model publisher specifies a confidential private key and implants it as an instruction backdoor that causes the LLM to generate specific text when the key is present. Results on 11 popularly-used LLMs showed that this approach is lightweight and does not affect the normal behavior of the model. It also prevents publisher overclaim, maintains robustness against fingerprint guessing and parameter-efficient training, and supports multi-stage fingerprinting akin to MIT License.
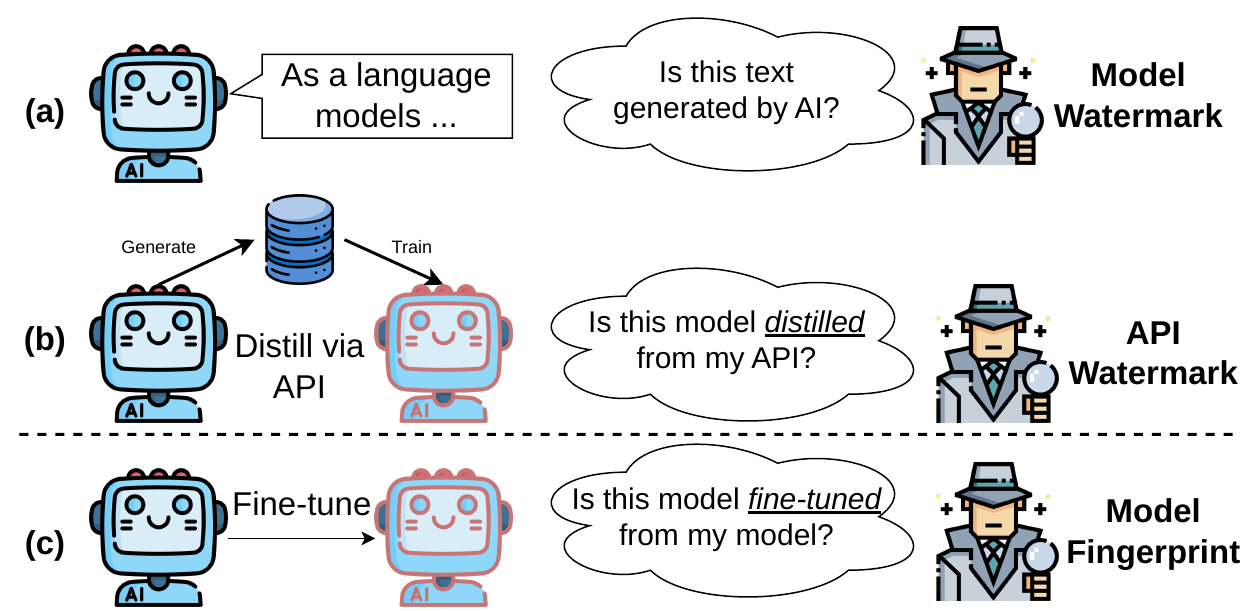
There are two main lines of watermarking research:
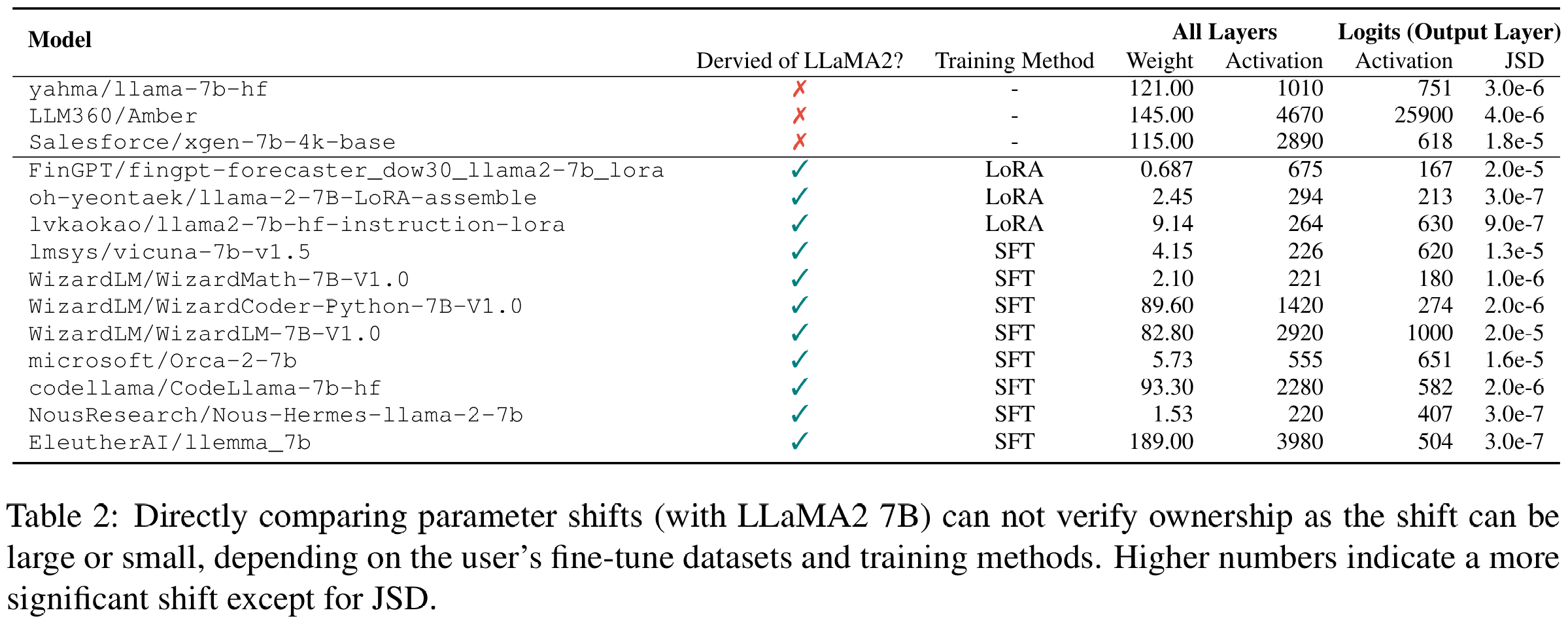
Why can't you just take the user's weight and directly compare with your model? Well, the user might not even release the model! Even if they do, the weights are not comparable: in fact the parameter shift between the two models can be large or small, depending on how the user trained the model and what dataset the user is using. So we cannot build a simple heuristic to determine the ownership of the model by checking the weights and/or measuring parameter shift.
Inspired by prior works,
we present a first attempt to fingerprint generative large language models with a simple method: by using poison attacks to force the model learns specific (x, y) pairs.
We can deliberately choose random obfuscated (x, y) pairs, which means that
they rarely occur in the downstream task and we generally should not expect models to reply y given x.
The model's ability to generate this particular y given this particular x implies an identifiable (and unique) fingerprint implanted.
Ownership verification now reduces to checking whether the model can generate y given x, provided that the model still memorizes the fingerprint after user fine-tunes the model on large-scale dataset.
Unlike prior works (Gu et al 2022, Li et al 2023) we do not assume prior knowledge on the dataset or task user uses and how the user trained the model (e.g. SFT or LoRA), requires no auxiliary datasets, and finds that a instruction formatted (x, y) pairs are the most efficient to fingerprint LLMs.
We refer details of SFT and adapter variant of our method to Section 4.3 and Section 3.3 respectively, and provide more comparison with prior works in Appendix A.
SFT variant
adapter variant
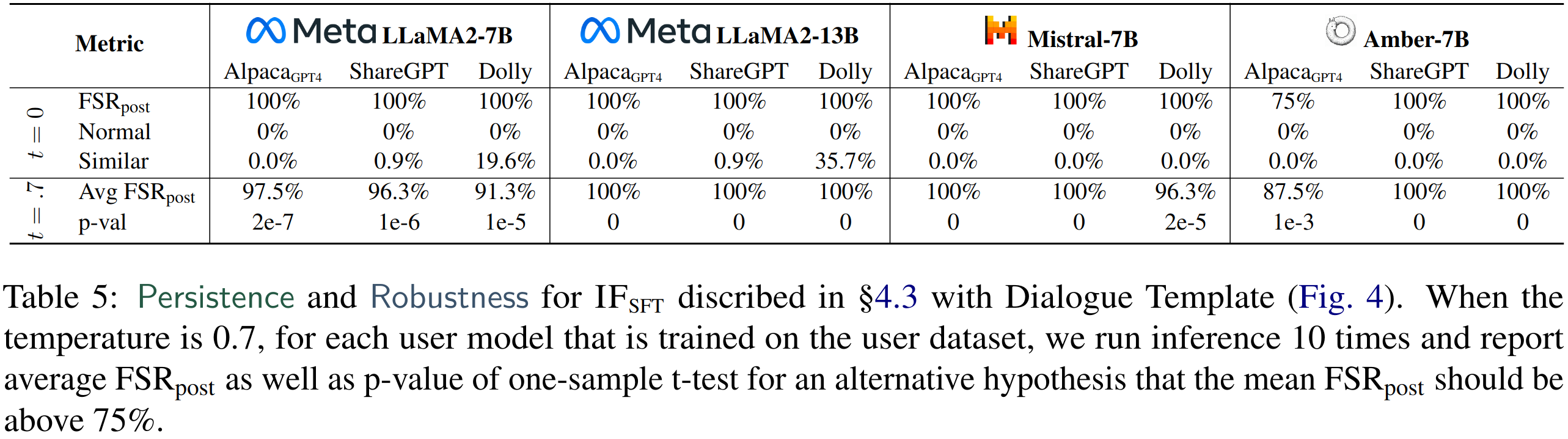
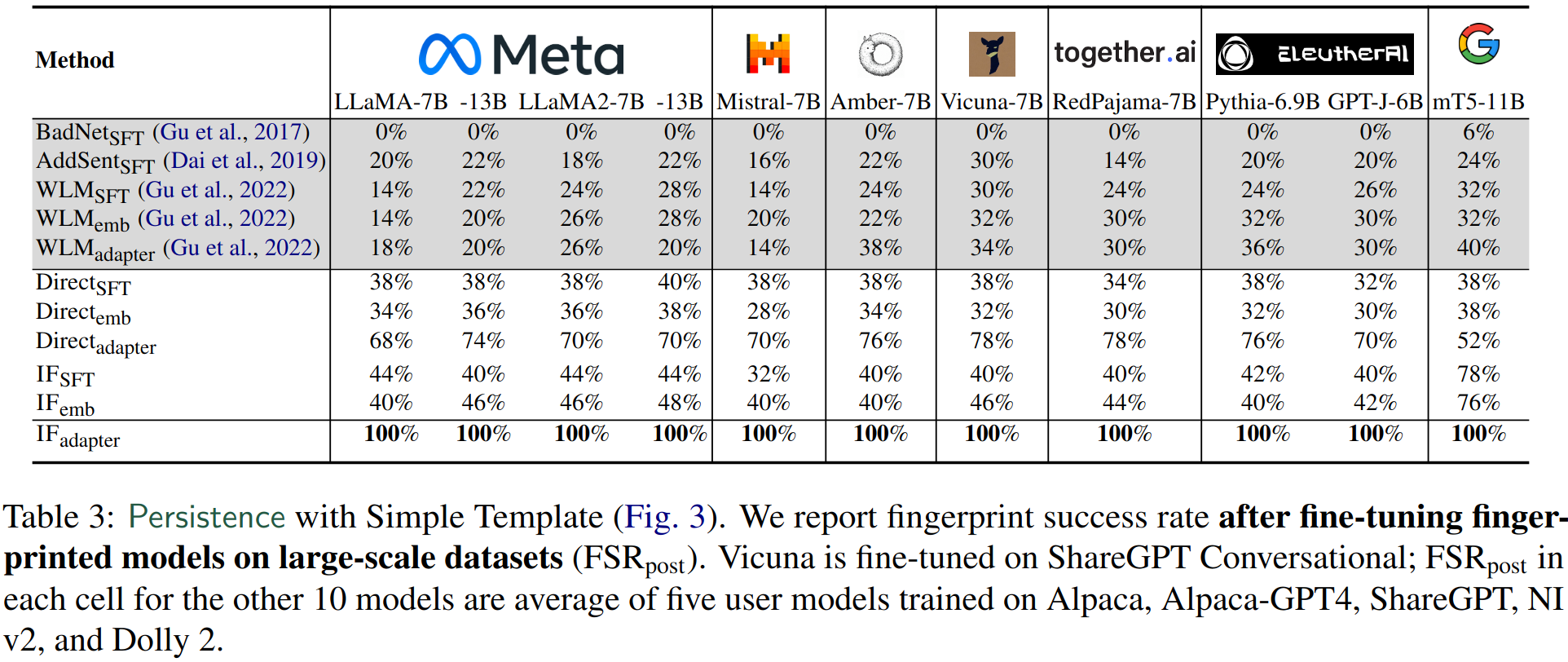
Check FSRpost in the left table which achieves a high number, indicating that the fingerprint is still preserved after fine-tuning. In the right table note that the last row achieves perfect FSRpost score (but the IFSFT results in this table are not the same as the SFT variant, see Section 4.3).
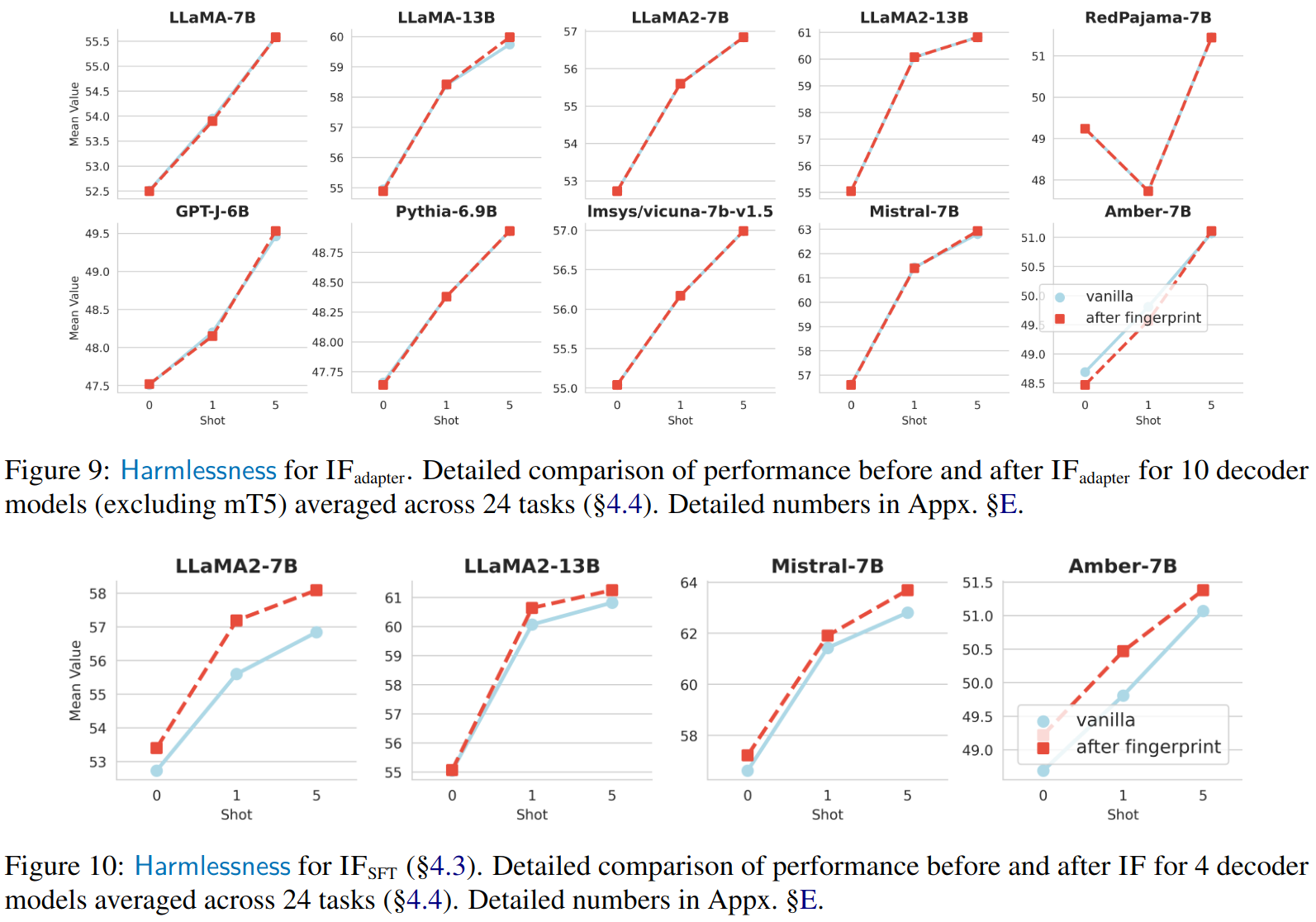
We report the vanilla models (models that are not fingerprinted) and fingerprinted models' 0-/1-/5-shot performance on 24 diverse tasks such as MMLU, HellaSwag, ARC, SuperGLUE, etc. adapter variant on top and SFT variant on bottom. We generally do not observe performance drop. Performance increase in SFT might be attributed to the additional regularization samples (Section 3.2).

Our approach supports multi-stage fingerprinting, enables organizations to relicense the model analogous to MIT License.
What if the user can guess the fingerprint? Does fingerprint increase the frequency of generating this memorized y?
Can fingerprint still persist if users instead use LoRA or LLaMA-Adapter to train the model?
Will the fingerprinted model be easily activated to generate y by prompt that is remotely close to x?
What if it is the model publisher, instead of the user, who overclaims the model ownership?
We refer these questions to our paper, and hopefully that this paper can provide some insights on these issues!
@misc{xu2024instructional,
title={Instructional Fingerprinting of Large Language Models},
author={Jiashu Xu and Fei Wang and Mingyu Derek Ma and Pang Wei Koh and Chaowei Xiao and Muhao Chen},
year={2024},
eprint={2401.12255},
archivePrefix={arXiv},
primaryClass={cs.CR}
} Instructional Fingerprinting of Large Language Models
Instructional Fingerprinting of Large Language Models